Deepseek-R1-ZERO时代来临前,为何无人尝试放弃微调对齐,借助强化学习构建思考链推理模型?
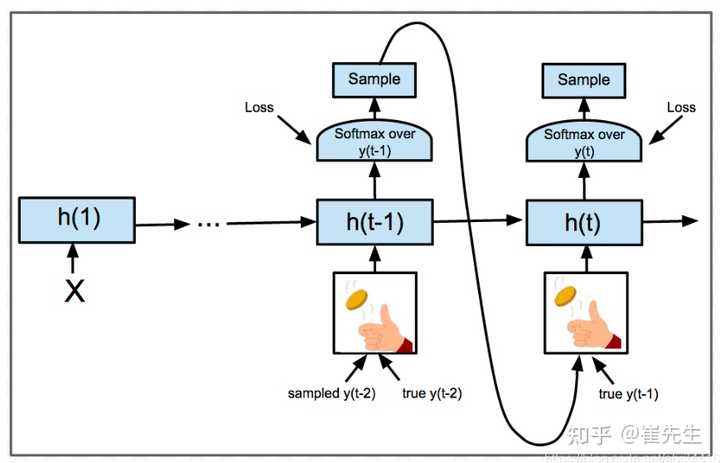
摘要:在Deepseek-R1-ZERO时代来临之际,尽管面临挑战,但无人尝试放弃微调对齐。这是因为强化学习构建的思考链推理模型具有强大的潜力,能够通过不断学习和优化,提高系统的决策能力和适应性。微调对齐是确保模型性...

摘要:在Deepseek-R1-ZERO时代来临之际,尽管面临挑战,但无人尝试放弃微调对齐。这是因为强化学习构建的思考链推理模型具有强大的潜力,能够通过不断学习和优化,提高系统的决策能力和适应性。微调对齐是确保模型性...
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号